Introduction
Aujourd’hui, de plus en plus d’entreprises adoptent des pratiques DevOps pour accélérer leur cycle de développement et de déploiement. Les applications développées en microservices font partie de ce mouvement. Elle offre davantage de souplesse dans la maintenance, le déploiement et la séparation des fonctionnalités. J’aborderais les différences entre une architecture orienté service SOA et une architecture en microservices, puis une présentation sur Docker, outil qui permet de mettre en place des conteneurs de services.
Architecture SOA, Microservices, kesako ?
SOA et microservice sont deux types d’architecture qui s’appuient sur une séparation de l’application en plusieurs composants. SOA (Service Oriented Architecture) est un pattern apparu dans les années 2000-2001 basé sur deux types de service : un consommateur et un fournisseur de services. Le consommateur est le point d’entrée où l’application va effectuer ses demandes au fournisseur via des protocoles comme REST. En architecture SOA, les ressources (base de données par exemple) sont partagées entre tous les fournisseurs de service. Une forte cohérence existe donc en interne dans ce type de configuration.
Le découpage en microservices est venu enlever cette inter-dépendance. Elle repose toujours sur SOA, mais chaque service ne partage que très rarement les ressources des autres. Cette configuration présente donc plusieurs avantages dans le sens où il est tout à fait possible de déployer seulement un service plutôt que toute l’application. Les risques de régression sont moins élevés ; cela fiabilise davantage l’application. Un microservice repose donc sur une et une seule fonctionnalité. Le découpage d’une application en microservices peut être métier ou technique (fonctionnalité technique). L’importance est de toujours garder cette indépendance entre chaque microservices.
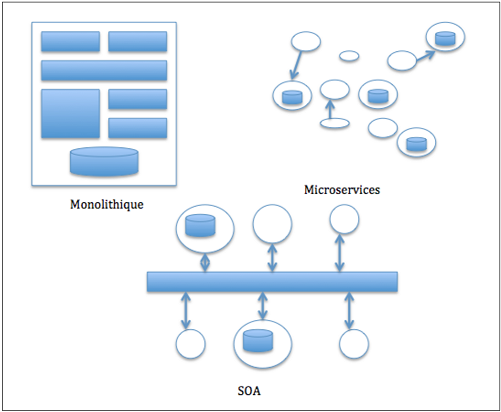
Un microservice peut se présenter comme une évolution de SOA mais attention, ce n’est pas une architecture qui peut répondre à tous les besoins. Elle peut dans certains cas être contre-productif.
D’accord, mais docker dans tout ça ?
Avant d’aborder Docker petit rappel sur le concept de virtualisation de serveurs (VM). Ce dernier nous permettra de mieux comprendre l’utilité de Docker dans cet article.
Auparavant, les serveurs contenaient les applications ou tout autres ressources pour rendre des services aux utilisateurs. Ces serveurs avaient un seul kernel (Linux, Unix, Mac ou NT). Ensuite est apparu le concept de virtualisation de serveurs, ie il était devenu possible d’avoir plusieurs serveurs virtuels indépendants au sein même de la machine. La puissance serveur, mémoire vive de la machine physique est donc partagé (… et configuré) parmi ce nombre de serveurs virtuels.
L’apparition des applications développées en microservices et l’approche de conteneurisation de services ont changé un peu le mécanisme de virtualisation.
Docker est une plateforme logicielle qui permet aux développeurs/opérationnels d’avoir des environnements (conteneurs) séparés, indépendants (séparation des services) les uns des autres, avec des configurations logicielles différentes (bibliothèque, environnement d’exécution, version de langage…), et reposant sur un seul Kernel (contrairement à la virtualisation). On dit alors que Docker virtualise le système d’exploitation (plutôt que la machine serveur dans le cas d’une machine virtuelle). Il faut savoir qu’il existe d’autre outil qui permettent la conteneurisation mais Docker reste le plus connu à ce jour.
L’avantage que représente Docker par rapport aux machines virtuelles est que l’environnement est strictement iso entre la dev et la prod. Dans une configuration de virtualisation, l’environnement de production des serveurs virtuelles devaient à chaque fois être identique sur les mêmes versions, configurations que les machines de développement, ce qui nécessitaient du temps…
Tandis que si une machine de développement utilise la même image que la machine de production, on est sûr qu’il n’y a pas de risques de régression. Et si un bug surgit en environnement de production, il est d’autant plus facile de reproduire ce problème en réutilisant un conteneur de cette image pour analyser et corriger l’erreur.
Les composants de Docker
Plusieurs termes techniques sont nécessaires pour mieux comprendre l'architecture propre à Docker.
1) Volume
Dans le grande majorité des cas, on a besoin d'accéder à des ressources qui ne sont pas forcèment situés dans son propre container.Par ailleurs, même s'il y a une communication entre containers pour envoyer/recevoir ces ressources, il faut savoir que la suppression d'un container détruit également toutes ses ressources à l'intérieur.
Pour remédier à ce problème, Docker à mis en place un système appellé Volume.
Cela permet au container d'utiliser les données directement sur le système hôte (et ainsi éviter d'aller chercher dans son container). Ce n’est pas une copie du container vers l’host mais bien un accès direct du container vers le File System de l’host.
Les volumes sont utiles lorsque l'on souhaite partager du code-source, ou bien une base de données entre plusieurs containers.
2) Port
Tout comme les volumes, les ports réseaux à l'intérieur d'un container ne sont pas directement accessibles depuis un host.Il faut penser à faire de la redirection de port pour y accéder. Ces redirections doivent donc être configuré au sein de chaque container Docker.
Lorsque l'on souhaite lier deux containers entre eux pour le partage de services, il existe un opérateur : --link
Cet opérateur permet de faire communiquer automatiquement deux containers (service Rails et le service MySQL par exemple). Un réseau privé est donc créé entre ces deux containers.
Cool, on y va ?
Après avoir installé Docker sur votre environnement (Windows, Linux, Mac), la première étape consiste à créer une première image. C’est à partir de celle-ci que l’on pourra ensuite créer nos différents conteneurs. L’image se définit comme l’environnement « référence » par rapport aux différents conteneurs. Cela permettra d’uniformiser et d’isoler les problèmes liés à des librairies, versions… puisque les conteneurs auront la même configuration logicielle.
Vous avez la possibilité de créer votre propre image sur votre serveur ou bien, au lieu de réinventer la roue à chaque fois, de télécharger une image qui répondent à vos besoins techniques.
Pour cela, il existe un Docker repository publique : https://hub.docker.com (prenez les dépôts officiels pour éviter les images malveillantes).
La création d’une image Docker se base sur un fichier qui s’appelle : Dockerfile. Il existe pas mal de commande pour personnaliser votre image (FROM, MAINTENER, ADD, RUN, CMD, …), je vous invite à consulter le site officiel de Docker pour les consulter.
Lorsque votre image est prête, avant de la lancer, vous devez la compiler avec la commande suivante :
docker build -t nomImagePour consulter la liste des images Docker enregistrée sur votre serveur :
docker imagesEnfin pour lancer votre image :
docker run nomImageLorsque vous démarrez une image, Docker va automatiquement créer un conteneur.
Pour voir la liste des docker démarrées :
docker psComment découper mon application microservices sur Docker ?
De part sa configuration, Docker est un excellent outil pour la gestion des microservices :
Chaque conteneur lancé devient :
- Facile à rebuilder et être redéployer, rapide à démarrer/stopper
- Non impactant la performance de l’application
- Stateless
Voici un exemple d’architecture microservices (contenant 6 microservices) :
- Web : Fournisseur d’interface web. Les technologies peuvent être HTML/JavaScript côté client et NodeJs pour le serveur web.
- Rest : Fournisseur de service web sous forme d’API REST.
- Redis : Pour le stockage des données
- RabbitMQ : Bus d’évènement
- Email : Pour l’envoi de mail
- Twitter : Pour la publication de tweet sur la plateforme
Chacun de ses microservices seront placés dans un conteneur séparé. Notez bien que'il faut sauvegarder la base de données sur l’host pour pouvoir couper et relancer le container plusieurs fois sans perdre des informations ou tout simplement si le container venait à se couper.
Conclusion
Ceci était une présentation globale de déploiement d’une architecture en microservices sous Docker. A partir de cet environnement, il est aussi possible de greffer d’autres outils qui permettront aux développeurs/opérationnels d’améliorer leurs applications et leurs déploiements : Kubernetes (K8S) pour orchestrer les conteneurs, Molecule pour la mise en place de test de code Ansible…